In the previous post we went in detail through Recurrent Neural Networks (RNN’s). We looked at how they are similar to MLPs and how they allow for a large improvement in processing data.
One main problem with RNN’s is that it’s still relatively difficult for the model to maintain information on something that has happened a long time ago. If in one sentence the subject turns out to be a male, in the next sentence the model should still remember this, and use “he” as a pronoun when referring to this person. One way to do this, is by extending the sequence length to large values, but this brings its own problems: exploding and or vanishing gradients because of the increased depth of the model.
Note
Exploding and vanishing gradients is a general problem of deep neural networks. In an earlier blog post we discussed this in the context of deep neural networks for vision applications.
Although there are multiple ways of dealing with this problem such as normalization and initialization, the Long short-term memory (LSTM) layer is another way to deal with this. Instead of increasing the sequence length (and thus increasing the depth of the model), it aims to have a better technique for remembering the past.
Architecture and Intuition
To discuss the LSTM architecture, let’s start by looking back at RNN’s. In the previous post, we ended up with the following diagram displaying an (unrolled, single layer) RNN with a sequence length of 3:
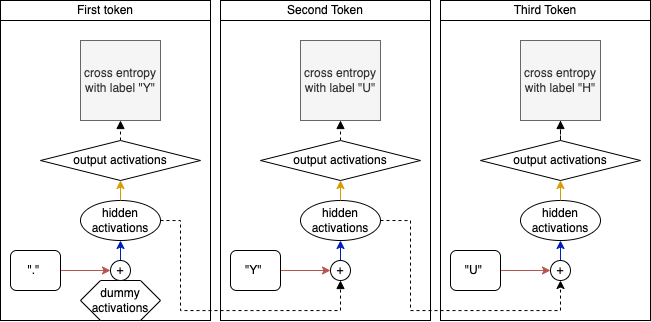
Unrolled 1 layer RNN processes a single batch with a sequence length of 3
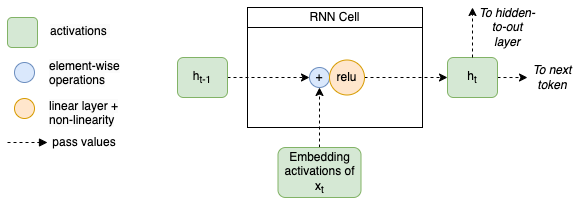
If we zoom in on the processing of one token (timestep) we can generalize this to the image below. In the middle, we have the RNN Cell which in terms of the image above, is the combination of the addition and the blue arrow (the hidden to hidden linear layer). On the left we see the previous hidden state entering the RNN cell, and on the bottom we have the embedding activations of the input entering the cell (this is what comes out of the red arrow in the image above. The computation of the new hidden state (on the right), is simply the addition of both activations and a linear layer followed by a Relu activation. This hidden state is passed to the next token as well as to the output layer (the yellow arrow in the previous diagrams).
Details of the RNN cell
With this representation, it becomes easy to understand the LSTM. Since the only difference is the content of this RNN cell!
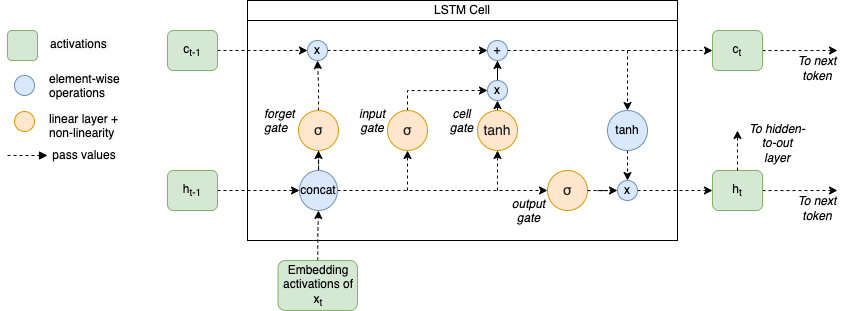
On the bottom left we see the (embedding activations of the) inputs \(x\) and the hidden state \(h\), similar to what we have seen in RNN’s.
The first thing that’s different from an RNN, is that the LSTM architecture uses a second (cell) state \(c\) (top left) besides the hidden state \(h\). Whereas in the RNN the hidden state is responsible for both keeping a memory of everything that has happened in the past, as well as having information for predicting the next token. These tasks are split in the LSTM, the cell state is responsible for keeping a memory and the hidden state is concerned with the next token.
Furthermore, the cell state update is not going through a neural network layer (orange circles), instead the LSTM can update this state by two element-wise operations (blue circles). This allows it to keep information (remember) for a long time.
The cell state is first multiplied by the output of the forget gate. These outputs first go through a sigmoid non-linearity and are thus between 0 and 1. Multiplications with 1’s mean that (parts of the) cell state is kept whereas values of 0 mean that (parts of the) cell state is removed (forgotton). The inputs to the forget gate are the concatenation of the previous hidden state and the (embedding activations) of the current input. However, there exist other LSTM’s where the previous cell state is concatenated with the hidden state and inputs (for example in the Peephole LSTM, in which all the gates get an input from the cell state).
Details of the LSTM cell
In the two gates that follow (input gate and cell gate), information is prepared to be added to the cell state. The input gate is outputting activations between 0 and 1 and is responsible for determining which cell state to update, and the cell gate is responsible for creating new candidate values. These two are multiplied together so that the outputs of the input gate filters the candidate values created by the cell gate.
Finally, the new hidden state gets computed and is a filtered version of the (updated) cell state. The cell state is first put through a tanh activation (values between -1 and 1) and then multiplied by sigmoid layer (values between 0 and 1). This sigmoid layer is essentially deciding which values of the cell state it wants to use for predicting the next token. The new hidden state is both outputted to the right (for the processing of the next token / timestep) as well as to the top (to be passed to the output layer similarly as in an RNN).
Now let’s discuss this process and the concepts in terms of a continuous text generation task. The cell state represents all the information about what has been generated previously: the subjects that the text is talking about, what is going on with the subjects, the style the text is written in (present tense, past tense etc). The multiplication of this cell state with the outputs of the forget gate, allow elements of the cell state to be forgotten. For example, if the current token (word) indicates that we are switching from present tense to past tense, the forget gate’s output should let the cell state know to drop it’s representation of the currently active (present) tense. The next two gates are responsible for adding new information into the cell state: e.g. preparing a representation of the past tense. Finally, the output gate should prepare a filter that the next word (let’s say a verb) should be created in the current style (which has now switched to past tense).
Although I have read about this intuition in multiple places, I am not sure whether it’s exactly correct. Nor whether it has been proven that an LSTM is doing things exactly in this way. My (current) belief is that researchers often not exactly know whether a certain intuition is correct or not. But that we simply try something, in which we can imagine that a neural network could learn something in a certain way. Whether the network is actually doing that thing, is not always clear. But I guess as long as it’s beneficial to performance, that’s the first thing to be happy about.
Now that we understand the LSTM, let’s code it up!
Data
Everything starts with training data, for a description see an earlier post
Code
import randomfrom functools importreduce, partialfrom pathlib import Pathfrom urllib.request import urlretrieveimport numpy as npimport torchimport torch.nn as nnimport torch.nn.functional as Fimport matplotlib.pyplot as pltimport torcheval.metrics as temimport fastcore.allas fcfrom nntrain.dataloaders import DataLoadersfrom nntrain.learner import*from nntrain.activations import*from nntrain.acceleration import*from nntrain.rnn import*########### Load the data ###########path = Path('./data')path.mkdir(parents=True, exist_ok=True)path = path /'names.txt'url ='https://raw.githubusercontent.com/karpathy/makemore/master/names.txt'_ = urlretrieve(url, path)withopen(path, 'r') as f: lines = f.read().splitlines()random.seed(42)random.shuffle(lines)train_size=0.8val_size=0.1train_lines = lines[0:int(train_size *len(lines))]val_lines = lines[int(train_size *len(lines)): int((train_size + val_size) *len(lines))]### Create vocabulary and mappings ###unique_chars =list(set("".join(lines)))unique_chars.sort()vocabulary = ['.'] + unique_charsc2i = {c:i for i, c inenumerate(vocabulary)}i2c = {i:c for i, c inenumerate(vocabulary)}
Last post the SequentialDataset and the VerticalSampler were introduced to load data in a way that fits RNN’s (and thus LSTM’s):
The creation of an LSTM cell is relatively straight-forward, by making use of the diagram we can simply put the arithmetic in a class:
class LSTMCell(nn.Module):def__init__(self, ni, nh):super().__init__() self.forget_gate = nn.Linear(ni + nh, nh)self.input_gate = nn.Linear(ni + nh, nh)self.cell_gate = nn.Linear(ni + nh, nh)self.output_gate = nn.Linear(ni + nh, nh)def forward(self, inp, h, c):# inp [bs, ni]# h [bs, nh]# c [bs, nh] h = torch.cat([h, inp], dim=1) # [bs, ni+nh] forget = torch.sigmoid(self.forget_gate(h)) # [bs, nh] c = forget * c # [bs, nh] inp = torch.sigmoid(self.input_gate(h)) # [bs, nh] cell = torch.tanh(self.cell_gate(h)) # [bs, nh] inp = inp * cell # [bs, nh] c = c + inp # [bs, nh] h = torch.sigmoid(self.output_gate(h)) # [bs, nh] h = h * torch.tanh(c) # [bs, nh]return h, c
Now let’s create an LSTMNet that uses this LSTMCell. This is a very similar network as the RNN we created in the previous post, we just have to iterate manually through the sequence length and sequentially call the inputs on the cell passing in the hidden and cell state:
class LSTMNet(nn.Module):def__init__(self, c2i, embedding_dim, hidden_size, bs):super().__init__()self.c2i = c2iself.bs = bsself.embedding_dim = embedding_dimself.hidden_size = hidden_size# register as buffer so that its moved to the device by the DeviceS Subscriberself.register_buffer('h', torch.zeros((bs, self.hidden_size)))self.register_buffer('c', torch.zeros((bs, self.hidden_size)))self.input2hidden = nn.Embedding(len(c2i), embedding_dim)self.lstm = LSTMCell(embedding_dim, hidden_size)self.hidden2out = nn.Linear(hidden_size, len(c2i))def forward(self, x): inputs =self.input2hidden(x) outputs = []for i inrange(inputs.shape[1]):self.h, self.c =self.lstm(inputs[:,i,:], self.h, self.c) outputs += [self.h]self.h =self.h.detach()self.c =self.c.detach()returnself.hidden2out(torch.stack(outputs, dim=1))def reset_hidden_state(self): device =self.h.get_device()self.h = torch.zeros_like(self.h).to(device)self.c = torch.zeros_like(self.c).to(device)
Last but not least, let’s sample some names with our LSTM:
@fc.patchdef generate(self:PyTorchLSTM, n=10, generator=None):# For unbatched input we need a 2D hidden state tensor of size [1, hidden_size]self.h = torch.zeros((self.h.shape[0], self.hidden_size)).cuda()self.c = torch.zeros((self.h.shape[0], self.hidden_size)).cuda() names = []for i inrange(n): name ='.'whileTrue: idx = torch.tensor([c2i[name[-1]]]).cuda() logits =self.forward(idx) s = torch.multinomial(F.softmax(logits, dim=1), 1, generator=generator) c = i2c[s.item()] name += cif c =='.': names.append(name)breakreturn names