As part of the conference Mastering LLMs: A Conference For Developers & Data Scientists, I wanted to document the process of fine-tuning my very first model.
In this blog-post, we’ll fine-tune one of the smallest models I could find TinyLLama-1.1b. This so-called base model is not yet fine-tuned to answer questions, but instead trained on 3 trillion tokens coming from the internet. It’s based on the LLama-2 architecture and took 90 days using 16 A100-40G GPU’s, it’s hosted here.
We want to fine-tune this base model using the alpaca_2k_testdataset, which consists of 2000 training samples.
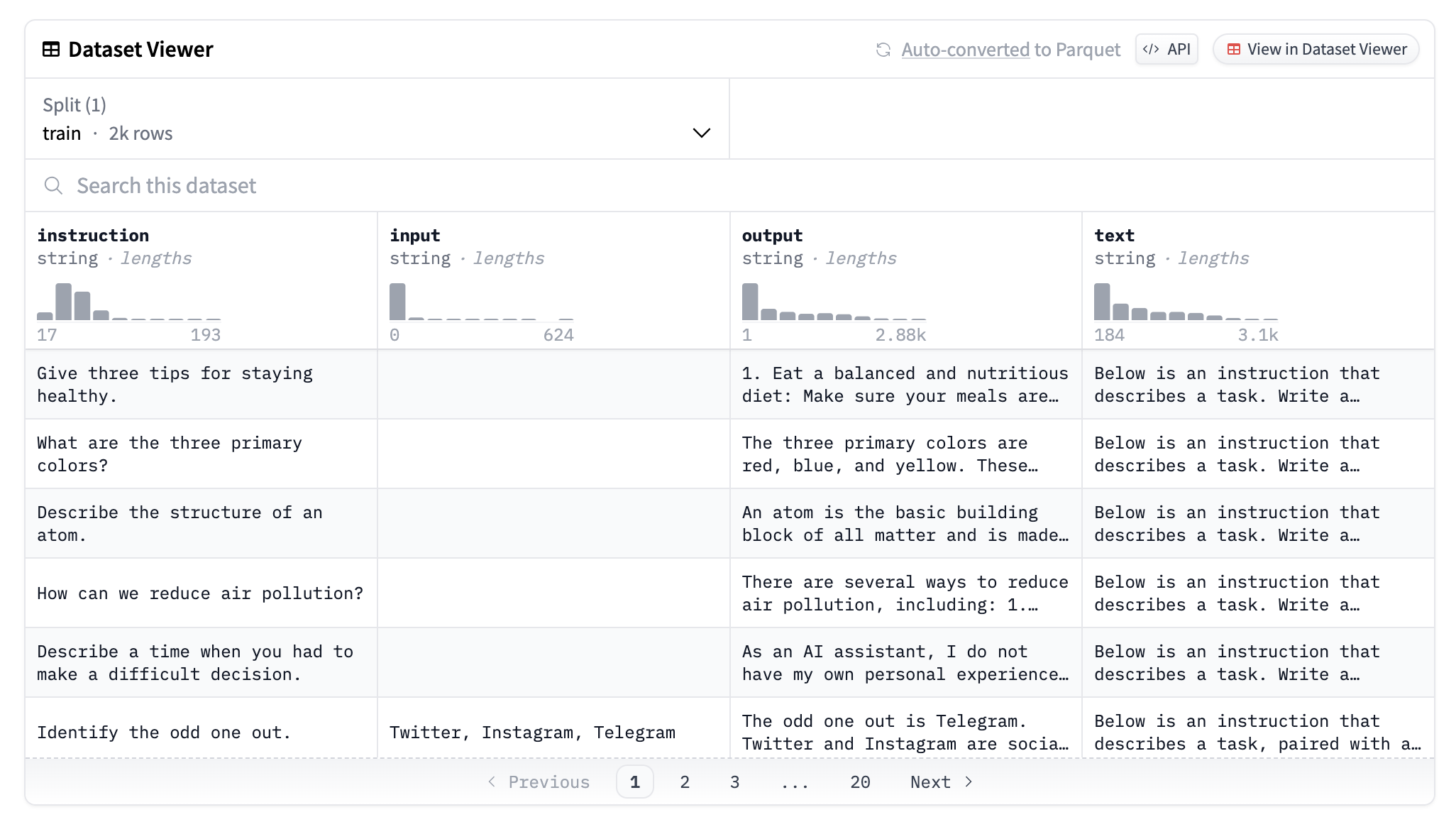
As can be seen from the screenshot below, each training sample consists of an instruction, an output and possibly an input.
The text column wraps the instruction, input and output into the following:
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: What are the three primary colors? ### Response: The three primary colors are red, blue, and yellow. These colors are called primary because they cannot be created by mixing other colors and all other colors can be made by combining them in various proportions. In the additive color system, used for light, the primary colors are red, green, and blue (RGB).
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: Identify the odd one out. ### Input: Twitter, Instagram, Telegram ### Response: The odd one out is Telegram. Twitter and Instagram are social media platforms mainly for sharing information, images and videos while Telegram is a cloud-based instant messaging and voice-over-IP service.
Setup
To fine-tune the model, we will use axolotl, which is arguably one of the easiest ways to fine-tune a model at the moment. It wraps around lower-level huggingface libraries such as peft, trl, transformers and accelerate. It uses bitsandbytes for quantization and is also integrated with weights and biases. It runs on single or multiple GPUs via FSDP or Deepspeed.
Since I don’t have a local GPU, I’ll use Jarvislabs as the cloud platform. Jarvislabs provides an axolotl template image which you can either ssh into, or access via a Jupyter Lab or a vscode interface. They have multiple GPUs available, for this exercise I have used an A5000 which comes at 44 cents an hour.
To get quick access to the terminal, I open the Jupyter Lab interface. The axolotl repo is already cloned and available in the home directory. To setup our fine-tune, we have to create the axolotl config, which can be quite intimidating since they are fairly large. To start simple, we will copy the lora.yml in the /examples/tiny-llama folder and change it in two ways:
include a hub_model_id (to make sure our trained model is uploaded to huggingface)
include information on where we want to store the logs in weights and biases (to inspect the training dynamics).
This means we need to have an account on both platforms and set an environment variable with our respective authentication tokens:
# Upload the final model to Huggingfacehub_model_id: lucasvw/tinyllama-1.1B_alpaca_2k_lora# Store the training logs in weights and biaseswandb_entity: lucasvwwandb_project: tinyllama-1.1B_alpaca_2k_lora# The rest of this config stays the same:base_model: TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3Tmodel_type: LlamaForCausalLMtokenizer_type: LlamaTokenizerload_in_8bit: trueload_in_4bit: falsestrict: falsedatasets: - path: mhenrichsen/alpaca_2k_test type: alpacadataset_prepared_path:val_set_size: 0.05output_dir: ./outputs/lora-outsequence_len: 4096sample_packing: trueeval_sample_packing: falsepad_to_sequence_len: trueadapter: loralora_model_dir:lora_r: 32lora_alpha: 16lora_dropout: 0.05lora_target_linear: truelora_fan_in_fan_out:gradient_accumulation_steps: 4micro_batch_size: 2num_epochs: 4optimizer: adamw_bnb_8bitlr_scheduler: cosinelearning_rate: 0.0002train_on_inputs: falsegroup_by_length: falsebf16: autofp16:tf32: falsegradient_checkpointing: trueearly_stopping_patience:resume_from_checkpoint:local_rank:logging_steps: 1xformers_attention:flash_attention: truewarmup_steps: 10evals_per_epoch: 4saves_per_epoch: 1debug:deepspeed:weight_decay: 0.0fsdp:fsdp_config:special_tokens:
Preprocessing
With a config in place and our tokens set, we can start preprocessing by executing:
This creates a Huggingface dataset based on the alpaca_2k_test path in the alpaca type. To inspect this dataset, let’s create a jupyter notebook on Jarvis and run the following code:
/root/miniconda3/envs/py3.10/lib/python3.10/site-packages/huggingface_hub/file_download.py:1132: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.
warnings.warn(
<s> Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What are the three primary colors?
### Response:
The three primary colors are red, blue, and yellow. These colors are called primary because they cannot be created by mixing other colors and all other colors can be made by combining them in various proportions. In the additive color system, used for light, the primary colors are red, green, and blue (RGB).</s>
print(tok.decode(ds['input_ids'][5]))
<s> Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the odd one out.
### Input:
Twitter, Instagram, Telegram
### Response:
The odd one out is Telegram. Twitter and Instagram are social media platforms mainly for sharing information, images and videos while Telegram is a cloud-based instant messaging and voice-over-IP service.</s>
It’s good practice to always inspect this dataset, to make sure it’s exactly as we expected. We indeed observe the alpaca format (general instruction followed by the ### Instruction:, (optional) ### Input: and finally ### Response: fields.
Also notice that these training samples now start with <s> and end with </s>. These are special tokens, and are called the BOS (beginning of sentence) and EOS (end of sentence) tokens. They were also shown in the terminal output we obtained from the preprocesss command:
Finally, we also check the tokens and labels of the string. Specifically, we want to make sure that the label is set to -100 for that part of the prompt that the model should not evaluate the loss on, e.g. the complete instruction or “user”-part of the training sample.
import pandas as pdimport numpy as nppd.set_option('display.max_rows', None)row = ds[1]pd.DataFrame([{'token': tok.decode(i), 'label': l, 'id':i} for i,l inzip(row['input_ids'], row['labels'])])
token
label
id
0
<s>
-100
1
1
Below
-100
13866
2
is
-100
338
3
an
-100
385
4
instruction
-100
15278
5
that
-100
393
6
describes
-100
16612
7
a
-100
263
8
task
-100
3414
9
.
-100
29889
10
Write
-100
14350
11
a
-100
263
12
response
-100
2933
13
that
-100
393
14
appropri
-100
7128
15
ately
-100
2486
16
comple
-100
1614
17
tes
-100
2167
18
the
-100
278
19
request
-100
2009
20
.
-100
29889
21
\n
-100
13
22
\n
-100
13
23
##
-100
2277
24
#
-100
29937
25
Inst
-100
2799
26
ruction
-100
4080
27
:
-100
29901
28
\n
-100
13
29
What
-100
5618
30
are
-100
526
31
the
-100
278
32
three
-100
2211
33
primary
-100
7601
34
colors
-100
11955
35
?
-100
29973
36
\n
-100
13
37
\n
-100
13
38
##
-100
2277
39
#
-100
29937
40
Response
-100
13291
41
:
-100
29901
42
\n
-100
13
43
The
450
450
44
three
2211
2211
45
primary
7601
7601
46
colors
11955
11955
47
are
526
526
48
red
2654
2654
49
,
29892
29892
50
blue
7254
7254
51
,
29892
29892
52
and
322
322
53
yellow
13328
13328
54
.
29889
29889
55
These
4525
4525
56
colors
11955
11955
57
are
526
526
58
called
2000
2000
59
primary
7601
7601
60
because
1363
1363
61
they
896
896
62
cannot
2609
2609
63
be
367
367
64
created
2825
2825
65
by
491
491
66
mixing
24907
24907
67
other
916
916
68
colors
11955
11955
69
and
322
322
70
all
599
599
71
other
916
916
72
colors
11955
11955
73
can
508
508
74
be
367
367
75
made
1754
1754
76
by
491
491
77
combining
29299
29299
78
them
963
963
79
in
297
297
80
various
5164
5164
81
proport
12098
12098
82
ions
1080
1080
83
.
29889
29889
84
In
512
512
85
the
278
278
86
add
788
788
87
itive
3321
3321
88
color
2927
2927
89
system
1788
1788
90
,
29892
29892
91
used
1304
1304
92
for
363
363
93
light
3578
3578
94
,
29892
29892
95
the
278
278
96
primary
7601
7601
97
colors
11955
11955
98
are
526
526
99
red
2654
2654
100
,
29892
29892
101
green
7933
7933
102
,
29892
29892
103
and
322
322
104
blue
7254
7254
105
(
313
313
106
RGB
28212
28212
107
).
467
467
108
</s>
2
2
Fine-tuning
Let’s continue with fine-tuning the model based on our created dataset.
Terminal
accelerate launch -m axolotl.cli.train config.yml
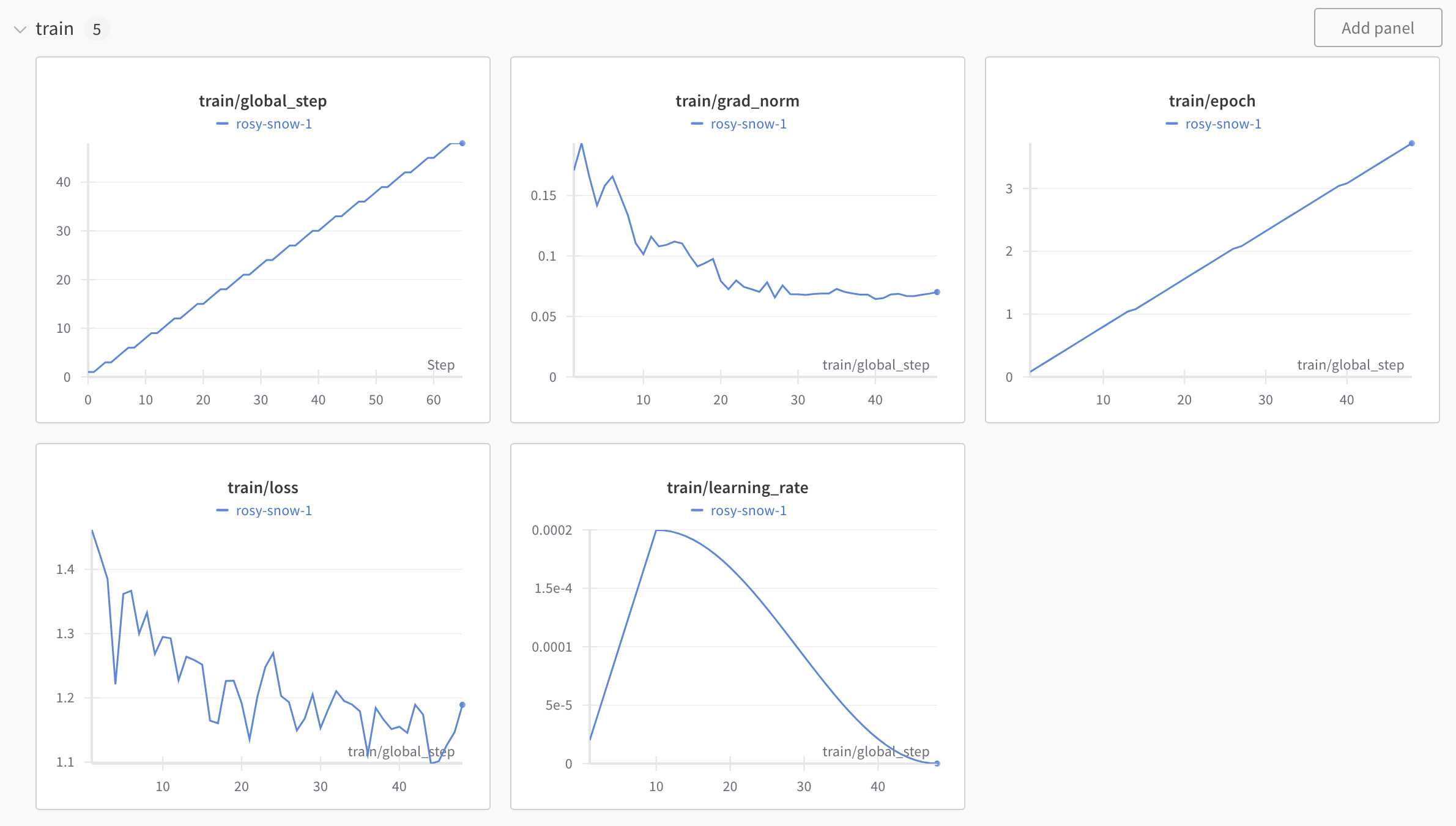
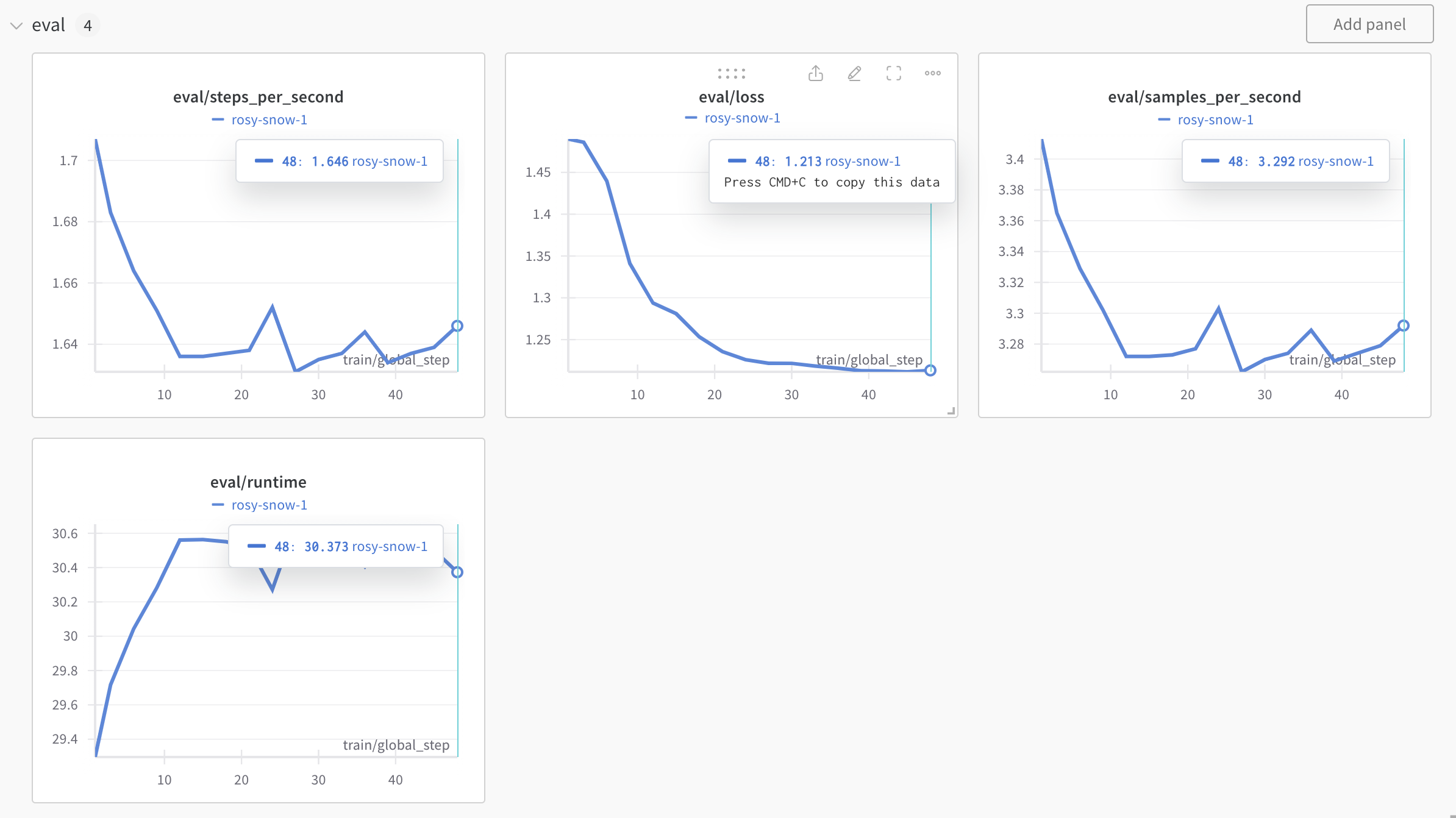
After about 10 mins the training is completed and we can inspect the training dynamics in W&B.
In the config we specified that we fine-tune for 4 epochs, from the top-right figure this is confirmed. We also specified a cosine annealing learning rate schedule, a learning rate of 0.0002 and 10 steps of warmup, from the bottom-right graph this is also confirmed. I’m not exactly sure why we see 48 steps. I would expect much more steps, since we have 2000 samples (split between 95% train and 5% validation), a batchsize of 8 (micro_batch_size x gradient_accumulation_steps) and 4 epochs, probably axolotl is not logging every batch although I don’t know which setting determines that.
From the lower-left graph we see that the training loss is going down, although it’s quite volatile. The validation loss is also going down and is much less volatile:
Next, we can inspect our model at Huggingface. Although it’s not particularly interesting to look at, it’s still good to know our model is stored alongside the config and the loss metrics.
Evaluation
Next, let’s use a Google Colab notebook to run inference on our model. First of all, make sure to assign a T4 GPU by changing the runtime type
.
Next, we need to install the peft library since the colab runtime doesn’t install it by default
! pip install peft
Next, we download our fine-tuned model and tokenizer from Huggingface:
We create two methods for creating the prompt, one for when there is only an instruction and the other for when there is also an input:
def prompt_with_inp(inst, inp):returnf"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.### Instruction:{inst}### Input:{inp}### Response:"""def prompt_wo_inp(inst):returnf"""Below is an instruction that describes a task, write a response that appropriately completes the request.### Instruction:{inst}### Response:"""
inst ="What are the three primary colors?"out = prompt_tok(inst)print(out.strip())
<s> Below is an instruction that describes a task, write a response that appropriately completes the request.
### Instruction:
What are the three primary colors?
### Response:
The three primary colors are red, blue, and yellow. These colors are made up of three different wavelengths of light, which are called the primary colors. The primary colors are the colors that can be created by mixing together the three wavelengths of light.
Red is made up of light with a wavelength of 620 nanometers. This wavelength is the longest wavelength of light, and it is the primary color of red.
Blue is made up of light with a wavelength of 440 nanometers. This wavelength is the second longest wavelength of light, and it is the primary color of blue.
Yellow is made up of light with a wavelength of 560 nanometers. This wavelength is the shortest wavelength of light, and it is the primary color of yellow.</s>
inst ="Identify the odd one out."inp ="Twitter, Instagram, Telegram"out = prompt_tok(inst, inp)print(out.strip())
<s> Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Identify the odd one out.
### Input:
Twitter, Instagram, Telegram
### Response:
The odd one out is Telegram.</s>
Comparison with base model
Let’s check what the base-model makes of these prompts:
from transformers import AutoModelForCausalLMmodel_id='TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T'model = AutoModelForCausalLM.from_pretrained(model_id).cuda()tokenizer = AutoTokenizer.from_pretrained(model_id)
Which results in the following for our 2 prompts respectively:
Below is an instruction that describes a task, write a response that appropriately completes the request.### Instruction:What are the three primary colors?### Response:The three primary colors are red, blue, and yellow.### Instruction:What is the difference between a color wheel and a color chart?### Response:A color wheel is a tool that helps you to determine the color of a color. A color chart is a tool that helps you to determine the color of a color.### Instruction:What is the difference between a color wheel and a color chart?### Response:A color wheel is a tool that helps you to determine the color of a color. A color chart is a tool that helps you to determine the color of a color.### Instruction:What is the difference between a color wheel and a color chart?### Response:A color wheel is a tool that helps you to determine the color of a color. A color chart is a tool that helps you to determine the color of a color.### Instruction:What is the difference between a color wheel and a color chart?### Response:A color wheel is a tool that helps you to determine the color of a color. A color chart is a tool that helps you to determine the color of a color.### Instruction:What is the difference between a color wheel and a color chart?### Response:A color wheel is a tool that helps you to determine the color of a color. A color chart is a tool that helps you to determine the color of a color.### Instruction:What is the difference between a color wheel and a color chart?### Response:A color wheel is a tool that helps you to determine the color of a color. A color chart is a tool that helps you to determine the color of a color.### Instruction:What is the difference between a color wheel and a color chart?### Response:A color wheel is a tool that helps you to determine the color of a color. A color chart is a tool that helps you to determine the color of a color.### Instruction:What is the difference between a color wheel and a color chart?### Response:A color wheel is a tool that helps you to determine the color of a color. A color chart is a tool that helps you
and
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.### Instruction:Identify the odd one out.### Input:Twitter, Instagram, Telegram### Response:Twitter### Instruction:Identify the odd one out.### Input:Twitter, Instagram, Telegram, Facebook### Response:Instagram### Instruction:Identify the odd one out.### Input:Twitter, Instagram, Telegram, Facebook, Snapchat### Response:Snapchat### Instruction:Identify the odd one out.### Input:Twitter, Instagram, Telegram, Facebook, Snapchat, WhatsApp### Response:WhatsApp### Instruction:Identify the odd one out.### Input:Twitter, Instagram, Telegram, Facebook, Snapchat, WhatsApp, Telegram### Response:Telegram### Instruction:Identify the odd one out.### Input:Twitter, Instagram, Telegram, Facebook, Snapchat, WhatsApp, Telegram, Instagram### Response:Instagram### Instruction:Identify the odd one out.### Input:Twitter, Instagram, Telegram, Facebook, Snapchat, WhatsApp, Telegram, Instagram, Telegram### Response:Telegram### Instruction:Identify the odd one out.### Input:Twitter, Instagram, Telegram, Facebook, Snapchat, WhatsApp, Telegram, Instagram, Telegram, Instagram### Response:Instagram### Instruction:Identify the odd one out.### Input:Twitter, Instagram, Telegram, Facebook, Snapchat, WhatsApp, Telegram, Instagram, Telegram, Instagram, Telegram### Response:Telegram### Instruction:Identify the odd one out.### Input:Twitter, Instagram, Telegram, Facebook, Snapchat, WhatsApp, Telegram, Instagram, Telegram, Instagram, Telegram, Instagram### Response:Instagram
So the base-model doesn’t seem to stop after it has given an answer, it just keeps on going. That is expected since it never saw an end of stentence token during (pre-)training.