from openai import OpenAI
client = OpenAI(
# for some reason ollama is running at port 6006 instead of the default 11434
base_url="http://localhost:6006/v1",
api_key="ollama", # required, but unused
)
chat_completion = client.chat.completions.create(
model="llama3:8b",
messages=[{"role": "user", "content": "Hello world"}]
)Having fun with llama3:8b
llm
ollama
llama3
langchain
langsmith
Intro
In this blog post I want to play around with Meta’s Llama-3:8b (instruct/chat) model, not so much as a way to rigorously benchmark it, but more as a way to get familiar with common tools in the large language model space such as Langchain, Langsmith and Ollama.
Running LLama-3 8b
One of the simplest ways to run an open weights model locally, is by using Ollama. Ollama is a very nice project that comes with a very simple CLI. It has a model registry containing many of the mainstream models such LLama2, Llama3, Mistral, Phi3 and Gemma. It’s also possible to add your own models to the registry, something that I’m planning to look into some other time.
Since I don’t have a powerful GPU locally, I will rely on Jarvis Labs for running this model. In fact, Jarvis provides an image which comes pre-installed with Ollama, so that’s pretty practical. After booting this image on an A5000 machine (44 cents/hour), let’s have a look what we get:
Terminal
~# ollama list
NAME ID SIZE MODIFIED
llama3:70b bcfb190ca3a7 39 GB 26 seconds ago
llama3:8b 71a106a91016 4.7 GB 26 seconds ago
llava:7b-v1.6 8dd30f6b0cb1 4.7 GB 26 seconds ago
llava:latest 8dd30f6b0cb1 4.7 GB 26 seconds ago
mixtral:text 43251bdd0575 26 GB 26 seconds agoSince we are only interested in the llama3:8b, let’s remove the other models
Terminal
~# ollama rm llama3:70b llava:7b-v1.6 llava:latest mixtral:text
deleted 'llama3:70b'
deleted 'llava:7b-v1.6'
deleted 'llava:latest'
deleted 'mixtral:text'The simplest way to start interacting with a model is by simply running ollama run llama3:8b. This opens a new shell, and we can start typing away:
Terminal
>>> Hello, how are you doing today?
I'm just a language model, I don't have feelings or emotions like humans do. However, I'm functioning properly and ready to help with any questions or tasks
you may have. It's great that you're reaching out and starting a conversation! Is there something specific you'd like to talk about or ask for assistance with?
>>> Send a message (/? for help)Great, that seems to be working. Now, let’s see how we can interface with Ollama in a programmatic way. Since beginning of this year, Ollama has built-in compatibility with the OpenAI Chat Completions API, making it possible to use more tooling and applications with Ollama locally. Let’s see if we can get that to work:
print(chat_completion.model_dump_json(indent=2)){
"id": "chatcmpl-386",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "A classic! Hello back to you! How can I help or chat with you today?",
"role": "assistant",
"function_call": null,
"tool_calls": null
}
}
],
"created": 1717142906,
"model": "llama3:8b",
"object": "chat.completion",
"system_fingerprint": "fp_ollama",
"usage": {
"completion_tokens": 19,
"prompt_tokens": 11,
"total_tokens": 30
}
}Awesome, now let’s move to Langchain.
Langchain
Langchain is a library to construct LLM‑powered apps easily. It provides tools to integrate LLMs with various data sources and APIs, facilitating tasks like natural language processing, data extraction, and automation. By offering a well documented modular library, Langchain helps with the development process, enabling engineers to focus on building innovative solutions rather than handling intricate implementation details.
Langchain has two different ways of interfacing with Ollama models, through the llm and the chatmodels API. Let’s start with the first:
from langchain_community.llms import Ollama
llm = Ollama(model="llama3:8b", base_url='http://localhost:6006')
query = "Tell me a joke"
llm.invoke(query)"Here's one:\n\nWhy don't scientists trust atoms?\n\nBecause they make up everything!\n\nHope that made you smile!"If we also want to include a system message, and possible have multi-turn conversations we can make use of the Messages API:
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
HumanMessage(content="Tell me a joke"),
]
llm.invoke(messages)"Here's one:\n\nWhy don't scientists trust atoms?\n\nBecause they make up everything!\n\nHope that made you smile!"We can also use the chatmodels API, which looks like this:
from langchain_community.chat_models import ChatOllama
llm = ChatOllama(model="llama3:8b", base_url='http://localhost:6006')
llm.invoke(messages)AIMessage(content="Here's one:\n\nWhy don't eggs tell jokes?\n\n(wait for it...)\n\nBecause they'd crack each other up!\n\nHope that made you smile!", response_metadata={'model': 'llama3:8b', 'created_at': '2024-05-31T13:22:38.906525723Z', 'message': {'role': 'assistant', 'content': ''}, 'done': True, 'total_duration': 7951646270, 'load_duration': 7360392062, 'prompt_eval_count': 14, 'prompt_eval_duration': 94730000, 'eval_count': 30, 'eval_duration': 360758000}, id='run-e0a07e06-9479-4dcf-b423-580a8f479896-0')This returns an AIMessage object, containing the actual string in the content key together with some more meta-data. To parse it out, we can use a StrOutputParser and combine both the llm and the parser into a chain:
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()
chain = llm | parser
chain.invoke(messages)"Here's one:\n\nWhy don't scientists trust atoms?\n\nBecause they make up everything!\n\nHope that made you smile!"Langsmith
Langsmith is the observability platform that comes with Langchain and is all about looking into traces. From these traces we can create datasets, which can in turn be used to fine-tune models with improved data. For any real world LLM application it’s important to look at such traces, understand what end-users are trying to do, and understand the failure modes of our application. Langsmith is a great tool to do that. To start storing traces, we simply include the following environment variables
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "<your-api-key>"Let’s look at the trace obtained from our very first Langchain invocation
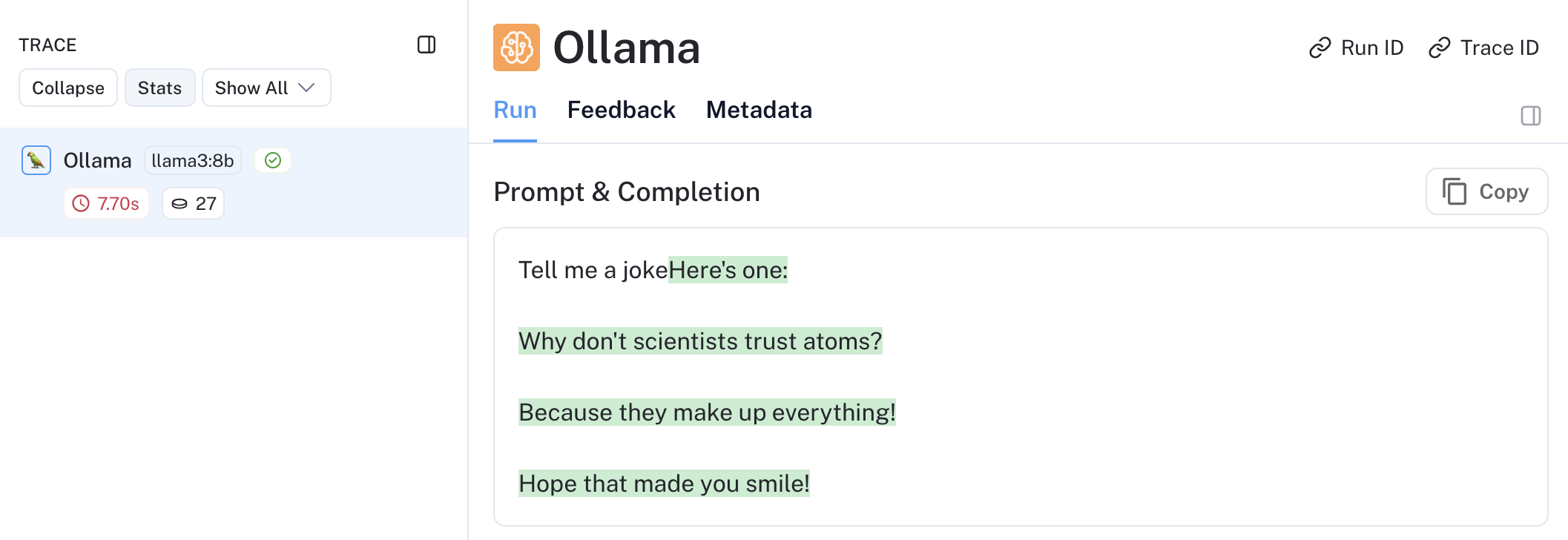
This is still a bit bare bones, but let’s look at the trace from our final invocation:
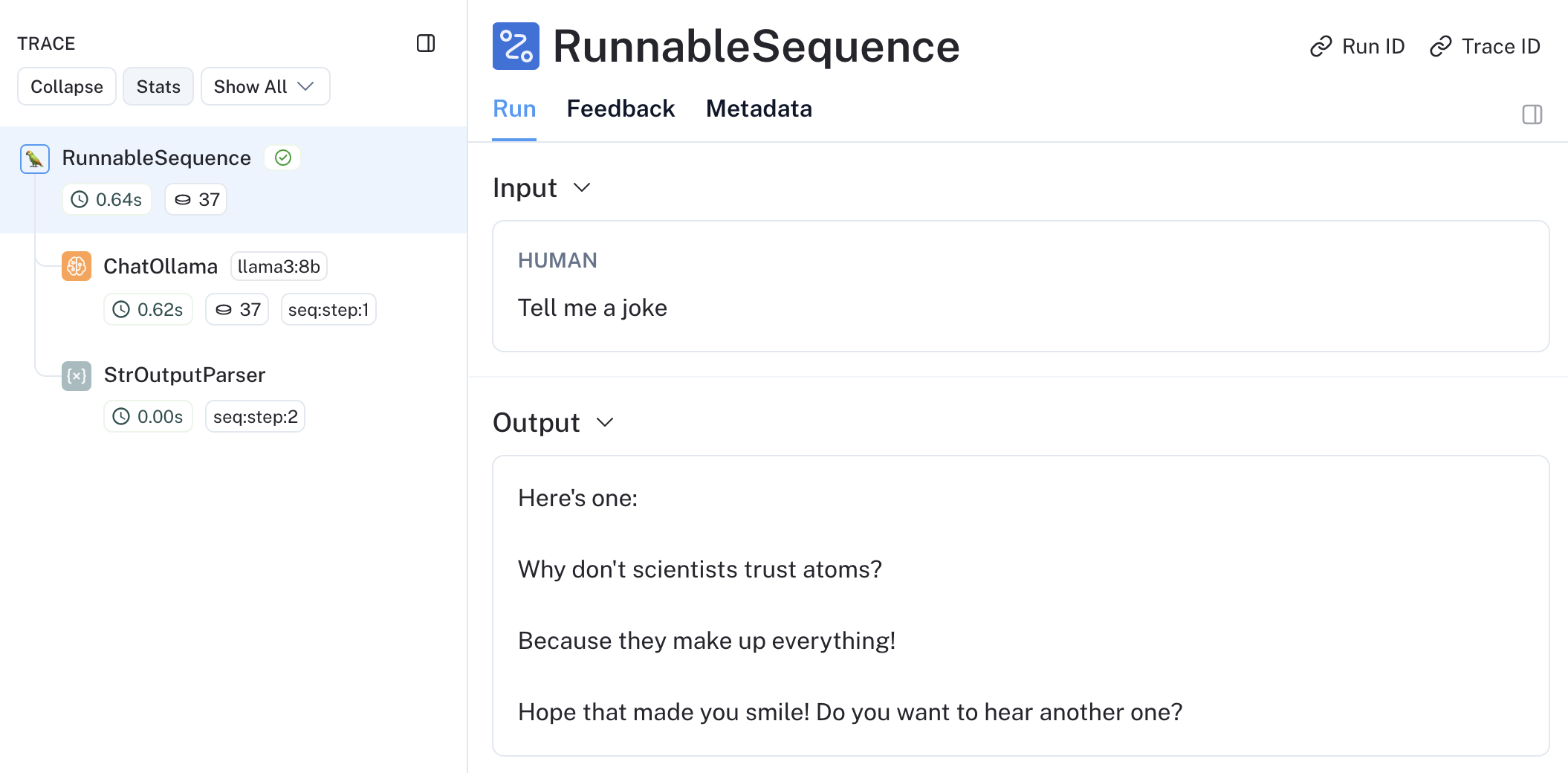
This is already starting to look better, we see the different steps of our chain and the inputs and outputs are rendering nicely. Especially for longer multi-turn conversations this can be very helpful.
Structured output
Oftentimes, we want the model to return structured output. For example, when we want to call an API based on the user inputs. Let’s specify some structure with pydantic and extract the json schema.
from pydantic import BaseModel, Field
import jsonclass Person(BaseModel):
name: str
age: int
class Address(BaseModel):
address: str = Field(description="Full street address")
city: str
state: str
class PersonAddress(Person):
"""A Person with an address"""
address: Address
json_schema = PersonAddress.model_json_schema()
json_schema{'$defs': {'Address': {'properties': {'address': {'description': 'Full street address',
'title': 'Address',
'type': 'string'},
'city': {'title': 'City', 'type': 'string'},
'state': {'title': 'State', 'type': 'string'}},
'required': ['address', 'city', 'state'],
'title': 'Address',
'type': 'object'}},
'description': 'A Person with an address',
'properties': {'name': {'title': 'Name', 'type': 'string'},
'age': {'title': 'Age', 'type': 'integer'},
'address': {'$ref': '#/$defs/Address'}},
'required': ['name', 'age', 'address'],
'title': 'PersonAddress',
'type': 'object'}Next, let’s see if we can get the model to output structured data:
schema = json.dumps(json_schema, indent=2)
messages = [
SystemMessage(
content="Please tell me about a person using the following JSON schema:"),
HumanMessage(content=schema),
HumanMessage(content="Now, considering the schema, tell me about a person named John who is 35 years old and lives on Pohlstrasse 85 in Berlin"
)
]
prompt = ChatPromptTemplate.from_messages(messages)
chain = prompt | llm | StrOutputParser()
result = chain.invoke({})
print(result)Based on the provided JSON schema, here's some information about a person named John:
**Name:** John (as per the schema, this is a string type field)
**Age:** 35 (integer type field)
**Address:**
* **address:** Pohlstrasse 85 (string type field)
* **city:** Berlin (string type field)
* **state:** Not specified in the schema, but since it's not required, I'll assume it's not provided (in reality, you would need to provide a state as well, such as "Berlin" or "Brandenburg")
So, John is a 35-year-old person who lives at Pohlstrasse 85 in Berlin.This is not bad, but it’s not json. However, we can use the format='json' argument in the ChatOllama definition. Let’s retry:
llm = ChatOllama(model="llama3:8b", base_url='http://localhost:6006', format='json')
chain = prompt | llm | StrOutputParser()
result = chain.invoke({})
print(result){"name": "John", "age": 35, "address": {"street": "Pohlstrasse", "number": 85, "city": "Berlin" }}And instantiating a PersonAdress object, shows that everything is good :)
PersonAddress(**json.loads(result))PersonAddress(name='John', age=35, address=Address(address='Pohlstrasse 85', city='Berlin', state=''))It would be interesting to compare this method to tools such as Instructor and Outlines. But for now, I’m pretty happy that LLama3:8b seems to be able to generate valid json based on these inputs.